엔씨소프트 AI 연구원이 말하는 ‘강화학습’

[게임플] 지난해 9월, 블레이드앤소울(이하 블소) 토너먼트 2018 월드챔피언십에서는 이색적인 경기가 펼쳐졌다. 바로 AI와 프로게이머 3인과의 대결이 펼쳐진 것. 이날 대결에서 AI는 전체 결과로는 2:1로 프로게이머에게 패했으나, 이는 프로게이머 수준의 AI가 처음 등장한 것이기에 개발 과정의 궁금증을 자아냈다.
오늘(24일) 경기도 성남시 넥슨 판교 사옥에서는 개발 노하우 공유의 장인 넥슨 개발자 컨퍼런스(NDC 2019)에서 그 궁금증을 해갈할 수 있었다. 이날 강연에서는 엔씨소프트의 게임 AI랩 문성빈 연구원이 ‘강화학습을 이용하여 프로게이머 수준의 블소 비무 AI 만들기’라는 주제로 강연대에 올랐다.
엔씨소프트는 비무 AI를 공격형, 밸런스형, 수비형 등 총 세 가지 형태로 개발했다. 블소의 여러 직업 중 연구하기에 용이했던 ‘역사’로 개발을 진행했으며, 주제에서 언급된 ‘강화학습’을 통해 해당 AI들은 점차 발전된 모습을 보였다.
문 연구원은 ‘강화학습’을 걸음마에 비유했다. 수많은 시도를 하고 실패를 겪지만, 자꾸 넘어지다보면 결국엔 걷는 법을 배우게 된다는 것이다. 좋은 행동은 강화하고 나쁜 행동은 약화하면서 결과적으로는 넘어지지 않는 AI를 만드는 것을 목표로 개발을 진행했다.
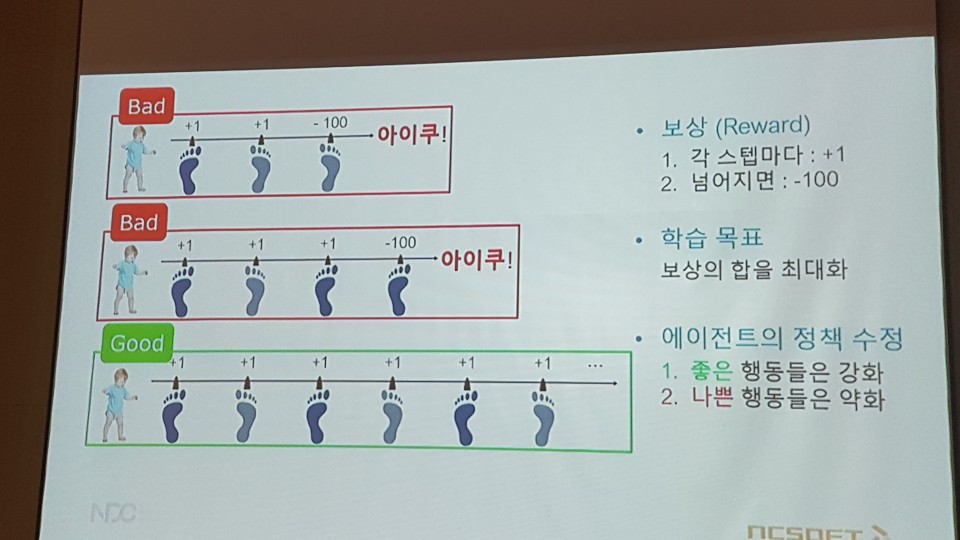
여기서 중요한 것이 보상인데, 처음에는 승패를 보상으로 지정했으나 이는 승패가 결정되기까지의 시간이 너무 오래 걸린다는 문제가 있었다. 이에 대해 개발팀은 HP의 득실을 추가 보상으로 제공해 위의 문제를 해결했다.
‘강화학습’을 진행하면서 블소 비무의 체계를 AI가 이해하도록 만드는 것도 중요했다. 블소의 비무는 크게 상태이상기, 저항기, 노액션(No Action)으로 나뉘며, 가위바위보와 같은 형태로 대결이 진행된다.
여기에서 오는 복잡성이 문제가 됐다. 문 연구원은 “사용할 수 있는 스킬의 수와 타겟팅, 그리고 평균 게임 길이를 합치면 10의 1800승이라는 경우의 수가 생긴다”며, “이는 알파고가 보였던 바둑에서의 복잡성보다 훨씬 높은 수치다”라고 말했다.
이에 대해 연구팀은 행동 공간의 축소로 그 해법을 찾았다. AI는 이동에 대한 경우의 수가 많으면 실제로 이동하는 거리가 길지 않고, 주변만 서성이게 된다. 하지만 1초 동안 이동 결정을 유지하면, 이동하는 거리가 줄어드는 것. 결론적으로 가짓수는 줄어들고 이동 결정의 효과는 늘어남을 알 수 있었다.
다음 문제는 실시간성. 블소의 비무 AI는 0.1초 단위로 즉각적인 행동을 취하기 때문에, AI가 생각할 수 있는 가짓수가 되려 줄어들게 된다. 여기에는 해법으로 인공신경망을 도입했다고 문 연구원은 설명했다.
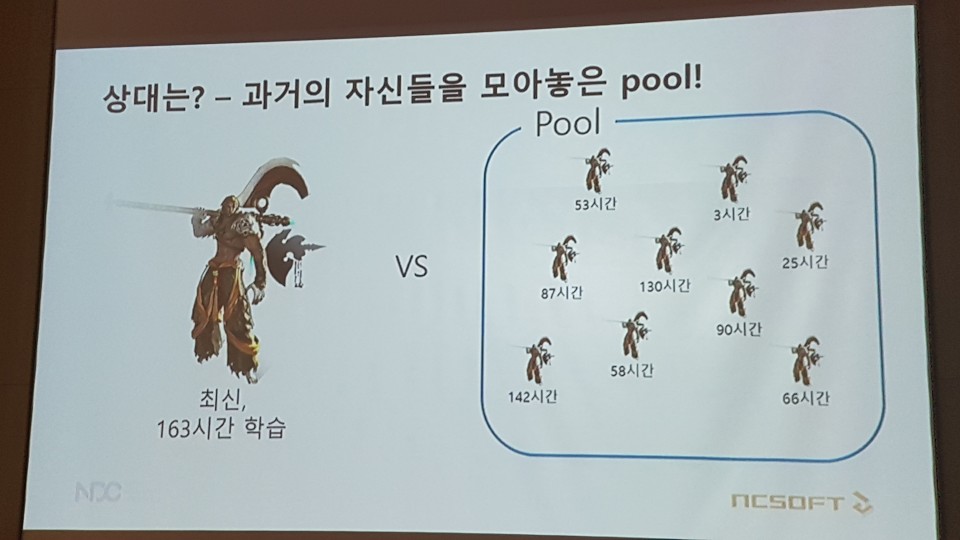
플레이 스타일이 단순화되는 문제에 있어서는 다양한 모델들을 상대로 학습하는 형태를 취해 해결법을 찾았다. 즉 ‘Self Play’. 과거의 AI 자신과의 비무를 통해 약점을 파악하고 이를 극복하는 형태를 취한 것이다.
실험 결과도 이러한 기대에 부응해 하나의 상대에 대해서만 강해지는 것이 아니라 여러 상대에게 일반적으로 강해지는 AI가 생성됐다. 첫 비무 상대였던 ‘무한의탑(블소 PvE 콘텐츠)’ NPC들과의 대결에서 왔던 문제점이 이를 통해 해결됐다.
앞서 언급한 공격형, 밸런스형, 수비형으로 전투 스타일을 부여하는 데에는 보상 변형을 해법으로 차용했다. 문 연구원은 “공격형은 상대에게 대미지를 가하는 것을 우선순위로 뒀고, 수비형은 자신의 HP를 지키는 것을 우선으로 하도록 설계했다”고 설명했다. 덧붙여 공격형은 시간에 따른 패널티를 둬 경기를 빠르게 끝내도록 만들었다.
전체적인 학습 절차는 100개의 시뮬레이션을 동시에 진행하는 것이다. 2017년 개발된 ‘에이서’ 알고리즘을 택한 이 절차는 병렬적으로 진행됐으며, 이는 새로운 AI가 계속해서 생성되도록 만들었다.
결국 AI의 상대는 과거의 자신들을 모아놓은 풀이었다. 즉 앞서 언급한 ‘Sef Play’가 빛을 발한 것이다. 문 연구원은 “초기 모델은 테스트를 위한 더미(Dummy)를 제압하는데 124초가 걸렸으나, 하루 학습 시에는 42초, 일주일 학습 후에는 20초가 걸렸다”라고 말했다.
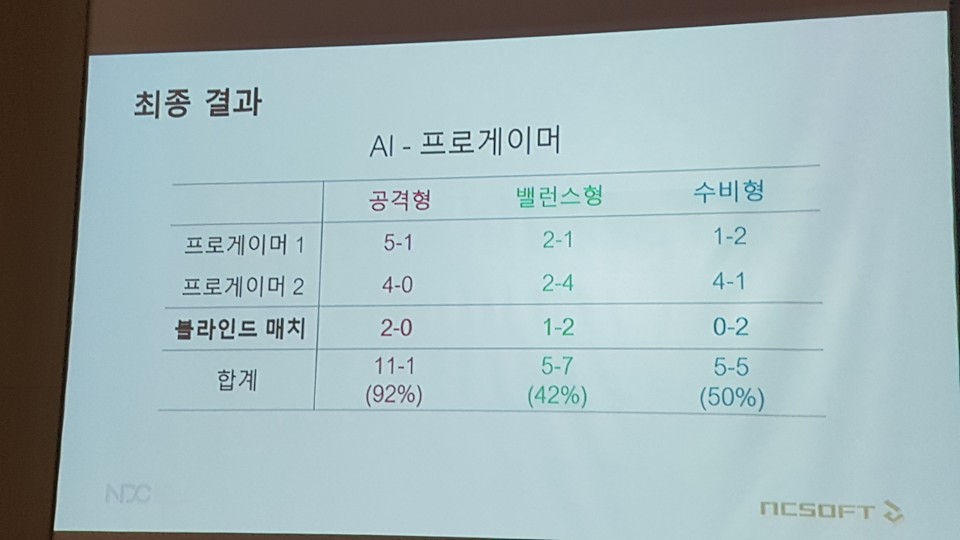
실제로 자료 영상에서 일주일 학습 후의 AI는 능숙하게 상태 이상기를 넣어 공격하며 손쉽게 상대를 제압하는 모습이었다. 이후 진행된 사전 테스트(대회 출전 이전)에서 AI는 테스트에 참가한 프로게이머를 상대로 밀리지 않는 모습을 보였다. 특히 공격형은 90%의 승률을 보일 정도로 압도적인 모습이었다.
서두에서 상술했듯 AI는 블라인드 매치로 진행된 대회에서도 만족스런 결과를 기록했다. 비록 수비형의 경우 0승 2패로 패배했지만, 밸런스형은 1승 2패를, 공격형은 2승 0패를 기록한 것이다.
결과적으로 복잡한 격투 게임에서도 강화학습을 활용한다면 프로게이머 수준으로 AI를 발전시킬 수 있음이 입증됐으며, 이는 보상을 적절히 조절한다면 전투 스타일을 부여할 수 있다는 것까지 증명했다. 또한 AI 자신의 과거 모델들의 상대 풀에 넣고 학습하는 것은 일반화에 도움이 되며, 결정 공간을 축소하는 것은 효율적인 탐색을 가능토록 했다.
문 연구원은 “전체적으로 세계 최고의 선수들과 비등한 모습을 보였다”며, “이러한 성과를 낸 이 AI가 처음이다”라고 비무 AI를 평가했다.
알파고를 지나 AI는 계속해서 발전하는 모습이다. 실제로 얼마 전에는 도타2 AI를 상대로 인간이 고전하는 모습이었다. 추후에는 AI가 인간에게 도전하는 것이 아닌 인간이 AI에게 도전하는 모습이 나올지도 모르겠다.
관련기사
- [NDC 2019] 넥슨 김동건 “마비노기처럼, 과거에서 미래로 선을 이어나가자”
- [NDC 2019] 한눈에 볼 수 있는 'NDC 2019' 아트전시회
- [NDC 2019] NDC 2019, 1일차 현장 모습
- [NDC 2019] “좋은 기획자는 적극적인 의사소통이 필수”
- [NDC 2019] 마비노기 영웅전의 사례로 보는 스토리텔링의 중요성
- [NDC 2019] 청소년의 게임 과몰입… ‘학업 스트레스가 주 원인’
- [NDC 2019] 신규 유저와 복귀 유저는 왜 게임을 다르게 볼까?
- [NDC 2019] 오락실의 추억을, NDC PLAY ZONE
- [NDC 2019] “드래곤하운드는 비주류 장르를 새로운 시각에서 접근한 작품”
- [NDC 2019] 카트라이더는 어떻게 역주행 할 수 있었을까?
- 프로게이머 잡는 AI, 어디까지 진화할까?
- 블소 토너먼트 2019, ‘사슬군도 단체전’ 채택… 총 상금 3억 원 규모